IOS 17、iPados 17、MacOS SonomaのAppleの新しい個人音声機能により、ユーザーはそれらのように聞こえる独自のデジタル音声を作成できます。これは、話す能力を失う可能性のある人々にとって大きな改善です。ユーザーはこの機能を使用して、声を出して話すテキストを入力し、コミュニケーションをより簡単で個人的なものにすることができます。 Appleを使用すると、ユーザーが独自のデジタル音声を作成できるようになりました。これは、アクセシビリティの重要な前進です。 Personal Voiceと呼ばれるこの機能は、機械学習を使用して、ユーザー自身の音声に非常によく似た合成音声を作成します。
あなたが話す能力を失うかもしれないか、将来のためにあなたの声を維持したいかにかかわらず、個人的な声はコミュニケーションと自己表現のための貴重なツールです。個人的な音声を設定するには、設定の下でアクセシビリティに移動し、個人の音声を選択し、手順に従って音声モデルを記録して生成します。このパーソナライズされた音声は、iCloudを介してさまざまなデバイスで使用でき、さまざまなアプリや設定で簡単に使用できます。 FaceTime、電話アプリ、またはその他のアプリを使用する人のために、パーソナルボイスは、録音されたオーディオとAIテクノロジーの組み合わせを通じて、リアルな音声レプリカを作成することでコミュニケーションを強化します。
個人的な声とは何ですか?
Appleの新しいPersonal Voice機能は、iOS 17で導入された革新的なアクセシビリティ機能で、ユーザーは独自の音声の合成バージョンを作成できます。このパーソナライズされた音声は、ライブスピーチとともに使用して、ユーザーが声を発言できない、または声を失っている場合、電話、ファセティタイムコール、または直接会話でさえ通信できます。
個人的な音声を作成するには、ユーザーは自分自身を記録して、ランダム化されたテキストのセットを約15分間読んでいます。この機能は、デバイス上の機械学習を利用してこのデータを処理し、ユーザーの自然な音声によく似た一意の音声モデルを生成します。
この技術は、スピーチやコミュニケーション能力に影響を与える条件を持つ個人の生活を大幅に改善する可能性があります。それは彼らが彼らのユニークなボーカルのアイデンティティを維持し、彼らが自分の声で話すことができなくても、本物で個人的な感覚で自分自身を表現することを可能にします。
どのように機能しますか?
このプロセスでは、iPhone、iPad、またはMacに150のフレーズを記録することが含まれます。 Appleの機械学習アルゴリズムは、これらの録音を分析して、あなた自身によく似た合成音声を作成します。
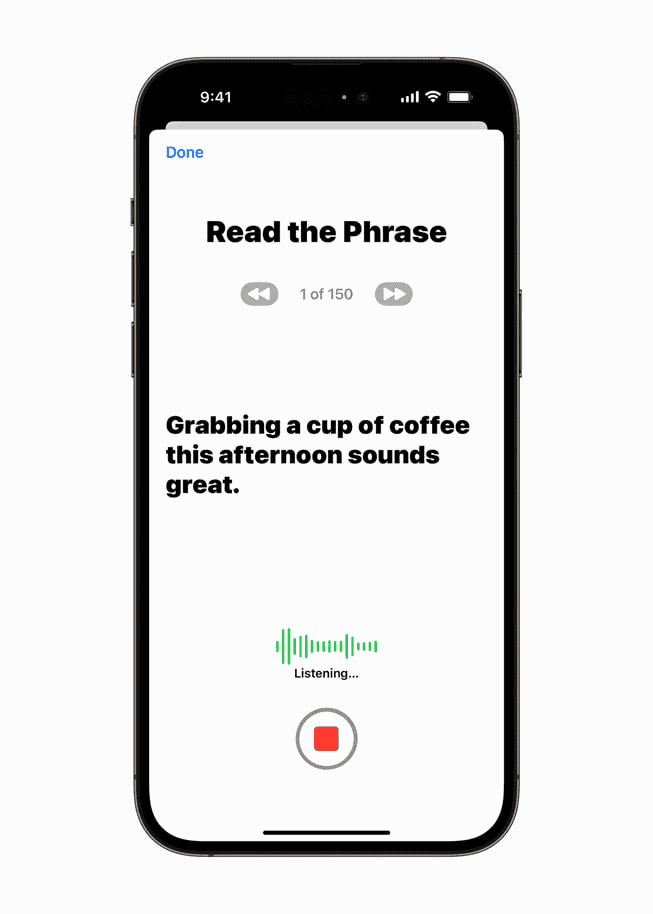
誰が恩恵を受けることができますか?
個人的な声は、ALSや他の病気のような状態のために話す能力を失うリスクがある個人向けに設計されています。ただし、誰でも使用して将来のために声を維持することができます。
あなたの個人的な声を作成する方法
- 行きます設定>アクセシビリティ。
- タップします個人的な声、次にタップします個人的な声を作成します。
- 画面上の指示に従って、150のフレーズを記録します。
あなたの個人的な声を使って
作成したら、あなたの個人的な声はさまざまな方法で使用できます。
- ライブスピーチ:電話、ファセティタイムコール、または直接会話中に話すタイプ。
- 支援通信アプリ:パーソナライズされた表現のために、あなたの個人的な音声を通信アプリに統合します。
- 毎日のコミュニケーション:テキストからスピーチへのニーズには、個人的な声を使用してください。
可用性と要件
個人の音声は、iOS 17以降を実行しているデバイス、iPados 17以降、およびMacOSソノマ以降で利用できます。少なくとも15GBのストレージを備えた互換性のあるiPhone、iPad、またはMacが必要です。
考慮事項
- プライバシー:Appleは、すべての音声データがデバイスで処理され、デバイスを離れることはないことを強調しています。
- カスタマイズ:ピッチと速度を調整して、個人的な音声をカスタマイズできます。
- 継続的な開発:Appleは、将来の更新で個人的な声を改善し続ける予定です。
キーテイクアウト
- iOS 17の個人的な音声は、録音されたオーディオからデジタル音声を作成します。
- ユーザーは、デバイス間でアクセシビリティを設定し、同期します。
- FaceTimeや電話などのアプリの通信を強化します。
個人の音声プロファイルの作成と管理
Appleデバイスで個人の音声プロファイルを作成および管理すると、音声障害のあるユーザーのアクセシビリティが向上します。重要なアクションには、記録、カスタマイズ、統合、およびセキュリティの確保が含まれます。
個人的な声を記録して設定します
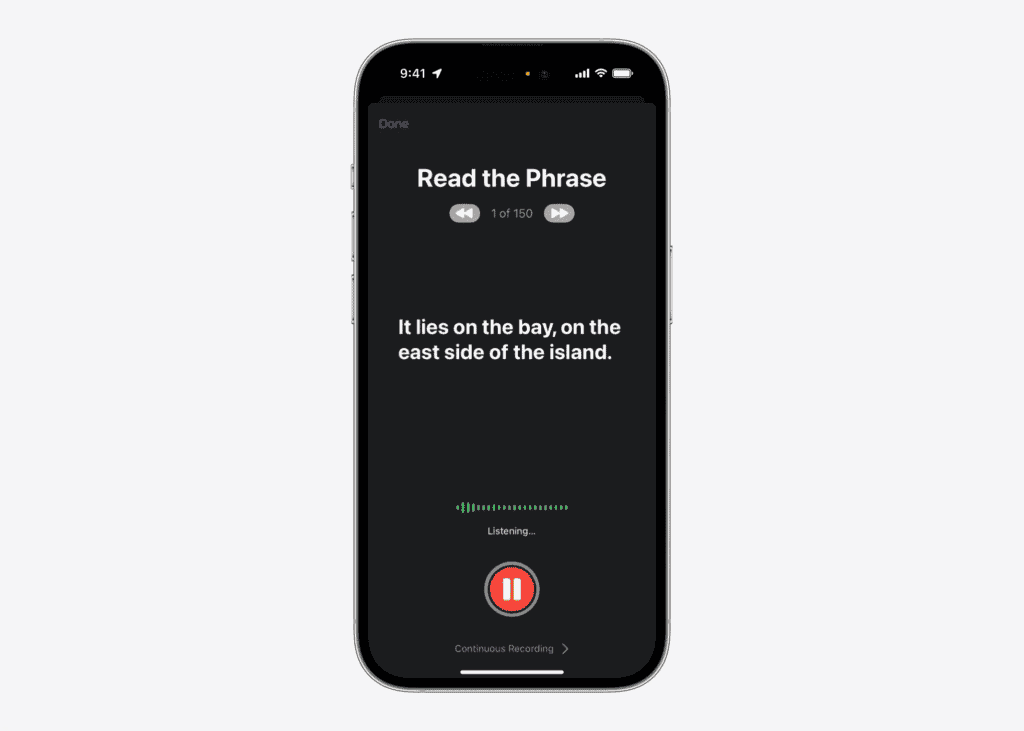
個人的な声のセットアップは、記録フレーズから始まります。ユーザーは、iPhone、iPad、またはMacで設定アプリを開きます。彼らはアクセシビリティ、そして個人的な声に移動します。このデバイスは、ユーザーに約150のフレーズを記録するように促します。
これらの録音は、機械学習を使用して一意の音声モデルを作成します。この音声モデルは、さまざまなアプリやサービスのテキストからスピーチ関数に使用されます。
アクセシビリティとコミュニケーションの強化
個人的な声は、筋萎縮性側索硬化症(ALS)などの言語障害のある人にとっては価値があります。パーソナライズされた明確な声を提供することにより、支援コミュニケーションに役立ちます。
この機能は、ライブスピーチで動作し、ユーザーが声を出して話されるテキストを入力できるようにします。 AACアプリと統合すると、日常のコミュニケーションニーズをサポートします。
Appleエコシステムとの統合
一度作成されると、個人の音声プロファイルは、Appleのエコシステムとシームレスに統合されます。 FaceTime、Siri、およびiOS、MacOS Sonoma、およびiPados 17のその他のアプリは、パーソナライズされた音声を使用できます。
これは、すべてのAppleデバイスで一貫した認識可能な通信を意味します。 iCloud Syncは、すべてのログインデバイスで音声プロファイルを使用できるようにし、統一されたエクスペリエンスを維持します。
セキュリティとプライバシー
Appleは、音声データの処理においてセキュリティとプライバシーを優先します。録音と音声モデルは暗号化され、ユーザー情報を保護するために安全に保存されます。エンドツーエンドの暗号化により、ユーザーのみが個人の音声データにアクセスできるようになります。
セキュリティをさらに強化するために、Appleはセットアッププロセス中にTouch ID、Face ID、またはPassCodeを使用します。これにより、認定ユーザーのみが個人の音声プロファイルを作成または変更できるようになります。
よくある質問
iOS 17のAppleの個人的な音声機能は、ユーザーに自分の音声のデジタルバージョンを作成して使用するユニークな方法を提供します。以下は、セットアップ、使用、およびその機能に関するいくつかの一般的な質問への回答を示します。
iOSデバイスに個人的な音声を設定するにはどうすればよいですか?
iOS 17を実行しているiPhoneで個人的な音声を設定するには、設定アプリ。タップしますアクセシビリティ、それから見つけます個人的な声の下スピーチセクション。画面上の指示に従って、個人的な声を作成します。
iOSエコシステムにおける個人的な声の重要な機能は何ですか?
個人的な音声により、ユーザーは自分の声のデジタルバージョンを作成できます。この音声は、テキスト間アプリケーションに使用できます。この機能は、高度な機械学習を使用して、ユーザーの音声を再現します。デバイスをよりアクセスしやすく、パーソナライズするのに役立ちます。
電話中に個人的な声を使用できますか?
現在、Appleは電話中の個人的な声の使用に関する詳細な情報を提供していません。ユーザーは、このテーマに関する新機能またはガイドについては、Appleからの更新または追加の手順を確認する必要があります。
Apple Personal Voiceアプリをダウンロードしてインストールする手順は何ですか?
現在のところ、個人的な声のための個別のアプリはありません。この機能はiOS17に組み込まれています。ユーザーは、設定APP Underアクセシビリティ。
Apple Personal Voiceの好みをカスタマイズする設定はどこにありますか?
個人の音声設定をカスタマイズするには、に進みます設定デバイスで。選択しますアクセシビリティ、選択します個人的な声の下スピーチセクション。ここでは、ユーザーは自分の声に関連するさまざまな設定を調整できます。
もっと詳しく知る:Appleを使用すると、IDアカウント間でアプリ、音楽などを移動できます
Apple Personal Voiceは何に使用されていますか?
Apple Personal Voiceは、独特の声を維持し、効果的にコミュニケーションをとるために話す能力を失うリスクがある個人を支援するように設計されています。ライブスピーチ機能とともに使用して、電話やファセティタイムコール中のユーザーのパーソナライズされた音声でテキストを声に出して声を出して声を出して、直接会話をすることができます。
あなたはあなた自身のsiriの声を作ることができますか?
現在のところ、あなたはあなたの個人的な声をSiriの声として直接使うことはできません。個人の音声機能は、主にコミュニケーションのためにライブスピーチアクセシビリティ機能と統合されています。
個人的な声が生成するのにどれくらい時間がかかりますか?
個人的な音声を作成すると、通常、最初の録画プロセスには約15分かかります。ただし、音声モデルの実際の生成は、デバイスが充電され、Wi-Fiに接続されている間に一晩で発生します。したがって、プロセス全体には約1日または少し時間がかかる場合があります。
セットアップには長い時間がかかり、150文を読むことが含まれることに注意してください。
個人的な声は良いですか?
レビューに基づいて、Appleの個人的な音声機能は有望ですが、その品質とユーティリティはユーザーの期待とユースケースによって異なります。 AIに生成された声が自分のものと非常に似ていると感じる人もいれば、ロボットまたは単調な品質に注目している人もいます。
150のフレーズを読むことを含むセットアッププロセスは長いと見なされ、一晩処理時間は不便です。生成された音声は、複雑な単語でも正確に発音できますが、ユーザーのスピーチの自然なニュアンスと変曲を常に捉えるとは限りません。
Siriに個人的な声を使用できない現在の声は、一部の人には見逃された機会と見なされています。
全体として、個人的な声は、声を失うリスクに直面しているユーザーにとって貴重なツールのように思われ、独自のボーカルアイデンティティのデジタル表現を保存できるようにします。他の人にとっては、生成された音声が完璧なレプリカではない場合でも、それは興味深い実験またはデバイスをパーソナライズする楽しい方法として役立つ場合があります。
また、Appleはその機能を改善し続けていることに注意することも重要です。そのため、将来の更新は現在の制限の一部に対処し、個人の音声機能の品質をさらに向上させる可能性があります。